
")

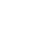

Metamodelos
As etapas de gerenciamento de um campo de petróleo demandam um elevado esforço e tempo computacional, principalmente para modelos complexos, com alta heterogeneidade, e problemas probabilísticos. Muitas vezes, processos de transferência de escala, quantificação de incertezas, análise de risco, ajuste de histórico, otimização e previsão da produção e tomada de decisão necessitam de muitas rodadas de simulação em busca de modelos quantificados e ajustados aos dados disponíveis com o intuito de prever uma produção confiável de um campo de petróleo.
Outro ponto importante a ser destacado é que as previsões de produção a partir de modelos numéricos de reservatório ajustados estão quase invariavelmente "errados", nos quais essas previsões, em muitas vezes, não se aproximam da produção observada em um período de tempo relativamente curto. O que não está claro é o quão errado eles poderiam estar em qualquer situação apresentada, e este fato tem levado a um aumento da pesquisa no campo de quantificação de incertezas em reservatórios de petróleo utilizando abordagens matemáticas e estatísticas. Além disso, compreender tal incerteza é crucial para tomada de decisão em todos os níveis de um gerenciamento de um campo de petróleo.
Ao longo dos últimos anos, estudos de formas rápidas, metamodelos, que são considerados modelos de baixa fidelidade, para “imitar” o simulador numérico de reservatórios têm sido desenvolvidos para acelerar uma parte do processo de gerenciamento do reservatório e, consequentemente, diminuir o tempo de tomada de decisão. Ao contrário de técnicas baseadas em soluções representativas, os metamodelos, construídos a partir de abordagens matemáticas e estatísticas, podem, em teoria, gerar modelos rápidos e consistentes para que possam substituir o simulador, modelo de alta fidelidade, nas etapas de estudo do reservatório de petróleo. Outro ponto importante a se destacar é que a qualidade do metamodelo gerado dependerá fortemente da abordagem matemática utilizada (algoritmo) e dos dados observados (histórico) utilizados para construí-lo.
Dentre os metamodelos mais utilizados na indústria de petróleo, destacam-se: os modelos de krigagem multivariada (KM); rede neural artificial (RNA); modelos de regressão polinomial (MRP); metodologia de superfície de resposta (MSR) e emuladores (EM).
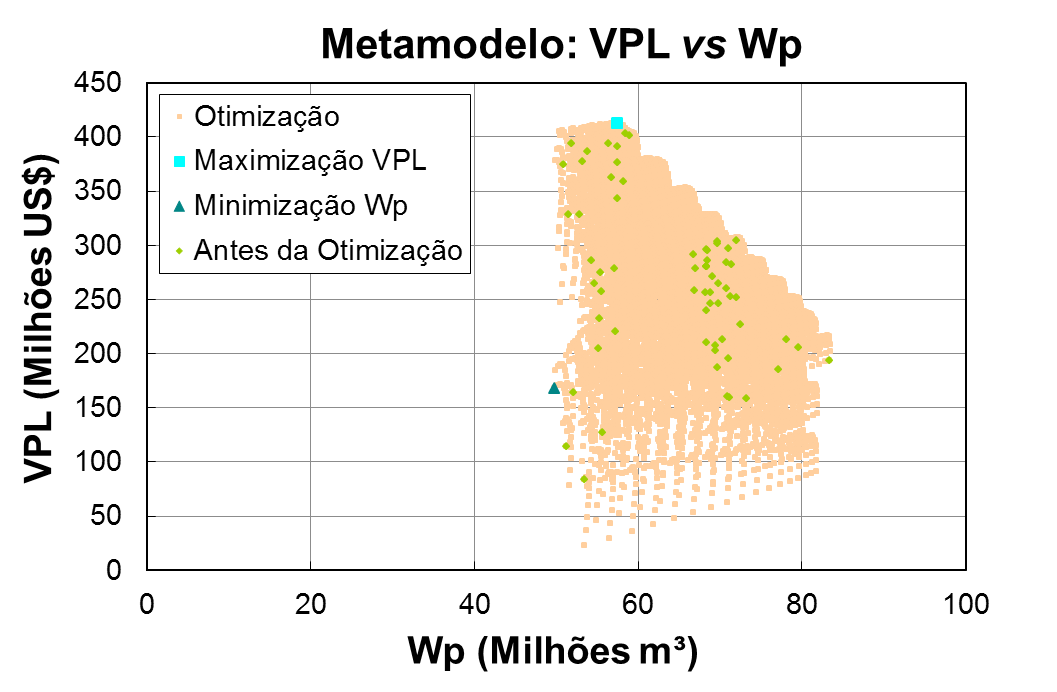
Emulador
Apesar do avanço nas técnicas de geração de metamodelos ao longo da última década, existem ainda muitas barreiras para a efetiva implantação em etapas de gerenciamento de reservatórios de petróleo. Estas incluem: o alto custo em tempo computacional para quantificar problemas probabilísticos; formas efetivas de parametrizar um modelo geológico para que seja realista e ainda fácil de ajustar aos dados de histórico; métodos efetivos de calibrar modelos numéricos a partir dos dados disponíveis do campo; análise dos erros de medição dos vários tipos de dados para os quais o modelo será calibrado; e técnicas efetivas para a previsão e tomada de decisão. Neste contexto, surge a técnica de emulação.
Essa técnica constrói um modelo estatístico para os erros ocorridos durante a simulação dos modelos numéricos de reservatório, prevendo tanto um erro médio quanto uma variância dos modelos que serão ajustados para que possam ser corrigidos com base em uma expressão matemática de desajuste do modelo. Ao inserir essas correções ao termo de ajuste, as respostas estimadas pelo emulador tenderão a ficar próximas daquelas que seriam obtidas utilizando um simulador numérico de reservatório. Além de utilizar o emulador para um tempo passado, ou seja, com dados de histórico, pode-se aferir também a cerca da previsão da produção utilizando a técnica de emulação.
O principal desafio desta linha de pesquisa está na velocidade e eficácia com que os modelos serão calibrados, combinando a abordagem de emulação linear de Bayes, desenvolvido pela Universidade de Durham, Departamento de Ciências Matemáticas, Estatística e Probabilidade do Professor Michael Goldstein, Dr. Ian Vernon e Camila Caiado, e algoritmos de amostragem estocástica precisos. O conceito chave é fazer valer cada simulação de alto custo computacional, destacando o aprendizado sobre a resposta com a metodologia Linear de Bayes. Com isso, as avaliações de alto custo computacional podem ser direcionadas em função das regiões onde a probabilidade de encontrar um modelo adequado/ajustado é alta. Uma vez em posse de uma série de modelos ajustados a partir da técnica de emulação, previsões de produção serão geradas utilizando uma metodologia estatisticamente válida, sendo outro objeto de estudo ao longo desta linha de pesquisa.